live since 2026-03-20 · 6:00 AM Pacific · daily
Wire
The repo is morning-intel; the product is Wire.
- Built for:
- One person — me. The willpower budget for “post on LinkedIn every morning” is finite; a cron has no willpower budget.
- Not built for:
- Anyone who needs a multi-tenant social scheduler. This is a single-user tool that owns one account and posts on its behalf.
The useful kind of automation is the kind that runs on a cron, not on willpower. Wire compiles two or three stories worth discussing, edits them to sound the way I write, and posts them to LinkedIn before I wake up. The hard part wasn’t the posting; the hard part was the editing.
The problem
A daily LinkedIn post is a small commitment that compounds badly. Skip a week and the algorithm forgets you exist; skip a month and you’re back to zero. Doing it well — finding genuinely interesting AI news, distilling it, writing it in a real voice — is twenty minutes a day. Doing it poorly is worse than not doing it. The middle ground is exhausting.
Wire moves the work to a cron. Research at 6:00, generate at 6:15, self-review, post at 6:30 and again at 9:30. By the time I’m at the desk, two posts have shipped. The willpower budget I would have spent goes to the actual work.
Decisions
Four calls that shaped Wire and what each one cost.
flipped2026-03
From Firecrawl to Google News RSS for source discovery. Firecrawl was the better tool but I was burning through credits faster than the value justified. RSS is free, infinite, and the dataset I want — recent AI news headlines — is exactly what RSS was built to publish.
cut2026-03
The Anthropic API for editing. The Max plan blocks API tokens issued to non-Claude-Code clients, which I respect; rather than fight it, I moved editing to a local
qwen3:8brunning on Ollama. The post quality was a step down for the first week and a step up by week three after I tuned the prompt.kept2026-03
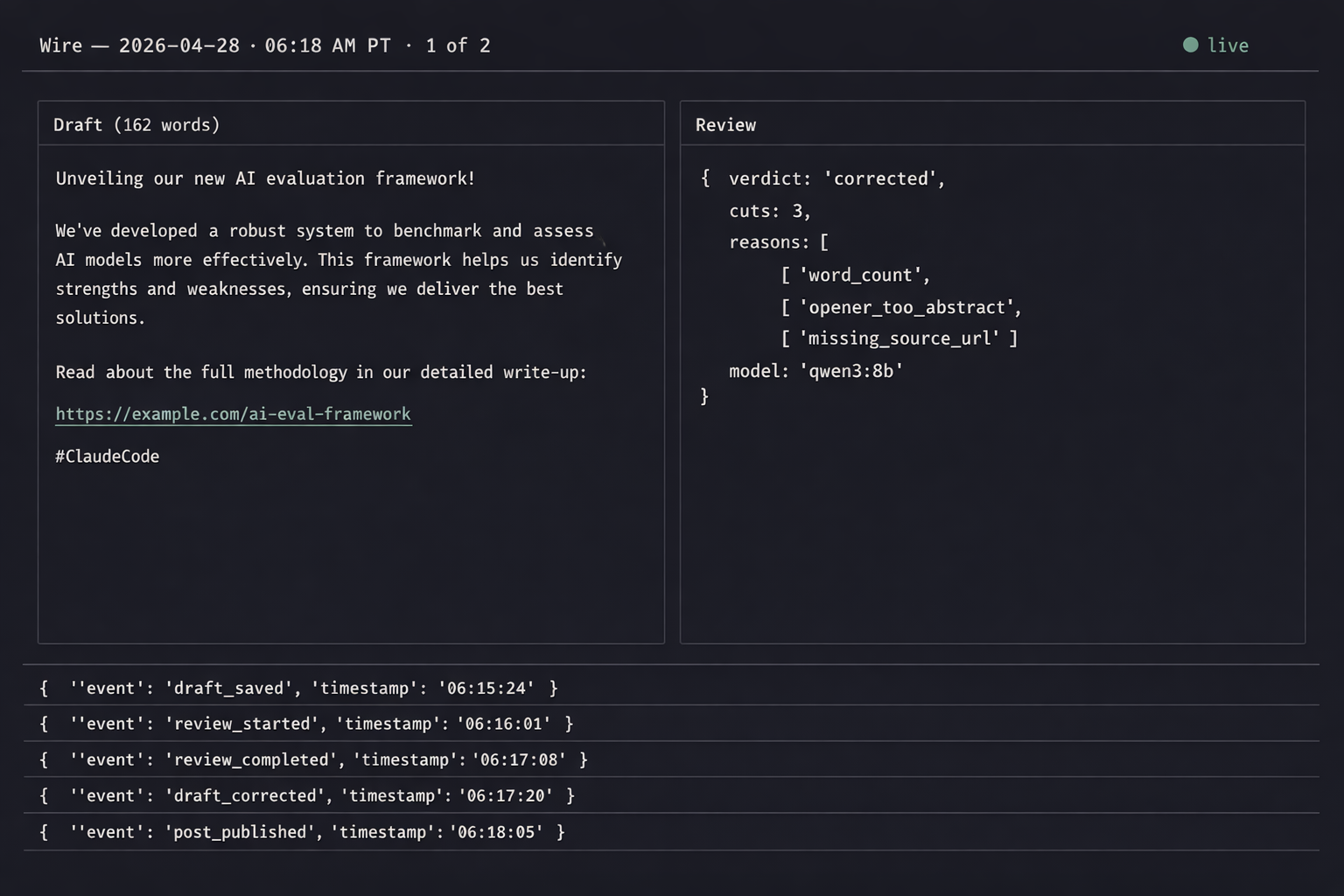
The self-review loop. After the model drafts a post, a second pass reviews it specifically for factual accuracy against the source articles. Roughly 1 in 8 drafts gets rewritten on review. The whole pipeline takes longer; the embarrassment cost of a wrong claim posted under my name is much higher.
refusedongoing
Auto-generated comments and reactions. The line for me is “automation drafts; human ships.” The post is automated because the cost of skipping a day is real; engagement is human because the cost of fake engagement is also real, just in the other direction.
The useful kind of automation runs on a cron, not on willpower.
System
One Python process, scheduled by Windows Task Scheduler, writing to a local SQLite database and a persistent Playwright Chromium session that stays logged into LinkedIn. The whole thing runs in ~90 seconds per pass and idles otherwise.
| Layer | Implementation | Purpose |
|---|---|---|
| Schedule | Windows Task Scheduler | Daily 6:00 / 6:15 / 6:30 / 9:30 triggers |
| Research | 13 RSS + 6 Google News | Parallel feed pulls; dedup by URL |
| Edit | Ollama qwen3:8b | Drafts, then self-reviews each draft |
| Post | Playwright (persistent) | Logged-in Chromium session, posts as me |
| Store | SQLite (10 tables) | Sources · drafts · review notes · history |
| Analytics | Daily scrape + ranker | What worked feeds the next day’s prompt |
# After the model drafts a post, send it back with the source
# finding for fact-checking. Roughly 1 in 8 drafts gets rewritten
# on review; the embarrassment cost of a wrong claim posted under
# my name is much higher than the cost of a second LLM call.
async def _review_draft(post: Post, findings: list[Finding]) -> str:
source = _source_finding_for(post, findings)
if source is None:
return post.content # nothing to fact-check against
prompt = _REVIEW_PROMPT.format(
finding_title=source.title,
finding_summary=source.summary,
finding_url=source.url,
draft_content=post.content,
)
try:
reviewed = await _call_llm(prompt)
if reviewed and reviewed.strip():
logger.info("Post %d reviewed: %s", post.id,
"unchanged" if reviewed.strip() == post.content.strip()
else "corrected")
return reviewed.strip()
except Exception as exc:
logger.warning("Review failed for post %d: %s", post.id, exc)
return post.content
{"t":"06:18:02-07","post":1881,"event":"draft_done","words":162,"model":"qwen3:8b"}
{"t":"06:18:04-07","post":1881,"event":"review_start","source":"news.ycombinator.com/item?id=43512..."}
{"t":"06:18:11-07","post":1881,"event":"review_done","verdict":"corrected","cuts":3,"reasons":["word_count","opener_too_abstract"]}
{"t":"06:18:11-07","post":1881,"event":"rules_applied","hashtags":1,"emojis":0,"url_present":true}
{"t":"06:18:13-07","post":1881,"event":"image_attached","path":"images/post_1881.png"}
{"t":"06:30:00-07","post":1881,"event":"posted","platform":"linkedin","reach_at_24h":4117}
Running it
Wire is private — it owns one LinkedIn account and posts on its behalf, which is exactly the kind of automation that benefits nobody from being multi-user. The setup shape is below in case it’s useful as a reference.
setup.ps1powershell# prerequisites: Python 3.13, Ollama, Chromium via Playwright
python -m venv .venv
.\.venv\Scripts\Activate.ps1
pip install -r requirements.txt
ollama pull qwen3:8b
python -m morning_intel.auth_setup # one-time LinkedIn login
schtasks /Create /SC DAILY /TN "Wire" /TR "python -m morning_intel" /ST 06:00What I’d do differently
The self-review loop should have shipped from day one, not week three. I wrote the first version without it because the model was “good enough”; the model is not good enough to be the only check on something that posts under my name. Review is the cheapest insurance available.
Picking sources by hand-curated RSS lists was the right call for v1 and is the wrong call for v3. A retrieval layer that scores stories on novelty + relevance + verified sources would beat the curated-feed approach by a wide margin. That’s the next milestone.
Acknowledgments
Wire stands on Ollama, Playwright, the qwen3 weights from Alibaba, the publishers who still ship RSS, and Python’s ecosystem of small, sharp libraries that make a 90-second daily job possible without inventing infrastructure.
← Index