local-first · policy-gated retrieval · running on-device
Companion
- Built for:
- Engineers who want a serious local AI surface they can audit, extend, and own — not a wrapper around someone else’s API.
- Not built for:
- Anyone who wants a polished consumer chat app today.
Most AI assistants assume the language model is the product. Companion doesn’t. The model is a service; the relationship — memory, presence, trust, timing — is the product. Policy is what keeps the relationship intact over years of use, and it is the only thing in the system that nothing else can route around.
The problem
A consumer-grade AI assistant is a single-session question machine. You type, it answers, the context evaporates, and the next session starts cold. That works for a search bar. It does not work for anything you want to live alongside for years — a journal, a research partner, a creative collaborator, a long-running second brain. Long-lived relationships need state; state on someone else’s servers is a relationship you don’t actually own.
Companion is the opposite shape. Memory, persona, audit log, and model weights all live on the user’s machine. Remote calls are deliberate and visible — never the default path. The architectural invariant is one line: every action that touches the world first clears a policy gate. No fast paths, no admin mode, no exceptions. The gate is the ground floor; everything else grows on top of it.
Decisions
The features are consequences. The decisions are the spine. Each one is dated and lives in a versioned ADR in the repo, so the reasoning is auditable later — including by me, when I forget why I made a call six months from now.
kept
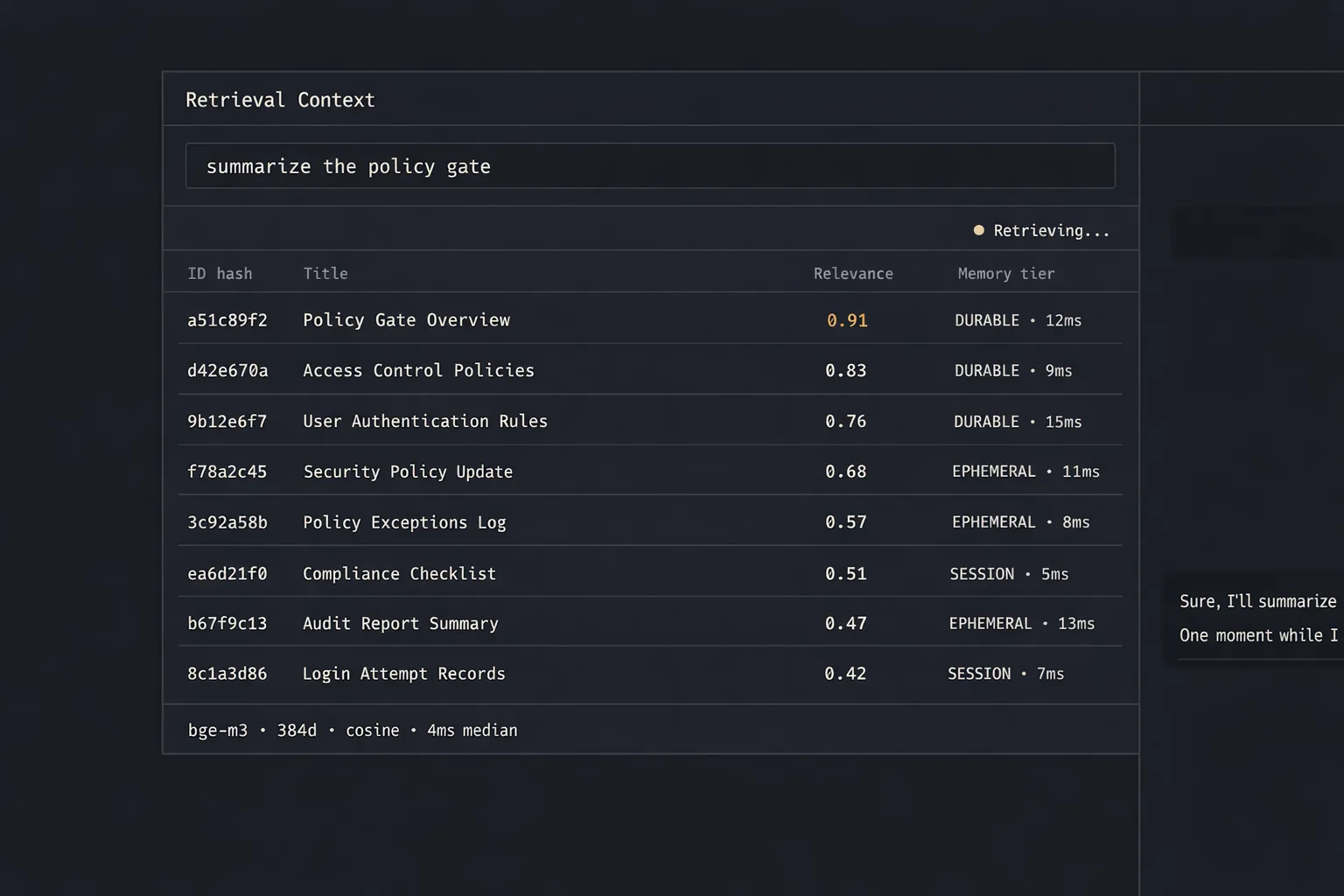
Sequential retrieval, post-memory and pre-prompt, with a hard 5-second bailout per phase. Parallel-with-timeout was the obvious move, but retrieval quality materially improves when the query vector is formed from the memory-augmented context, not the raw utterance. The bailout is a safety valve for a broken Ollama, not a normal-path latency target. ADR-0005 →
cut
wgpu::Limits::max_buffer_sizeas a tier-detection signal. On real hardware (24 GB RTX 3090 Ti) the Vulkan backend reportedu64::MAXwhile DX12 and GL reported 1 GB — the heuristic was measuring “did the driver expose a sentinel”, not VRAM. Tier classification now keys ondevice_type+ total system RAM, with the per-platform VRAM probe deferred to a future ADR. ADR-0008 →flipped
Embedding default from
nomic-embed-texttobge-m3. ~25-point retrieval-accuracy lift in recent RAG benchmarks (72% vs 57%); 1024-dim dense vs 768; 1.2 GB pull, still CPU-bounded. Text default pinned explicitly togemma4:e4brather than riding the:latesttag, which currently resolves to e4b but could drift to the 31B Dense variant — known FA-hang on prompts > 3–4K tokens. ADR-0003 →refused
A cloud-fallback route for the local model. The whole premise is that nothing leaves the device by default; an “escape hatch” that calls a remote API when the local model struggles erases the architecture. If the local model is wrong for the workload, the fix is a different local model.
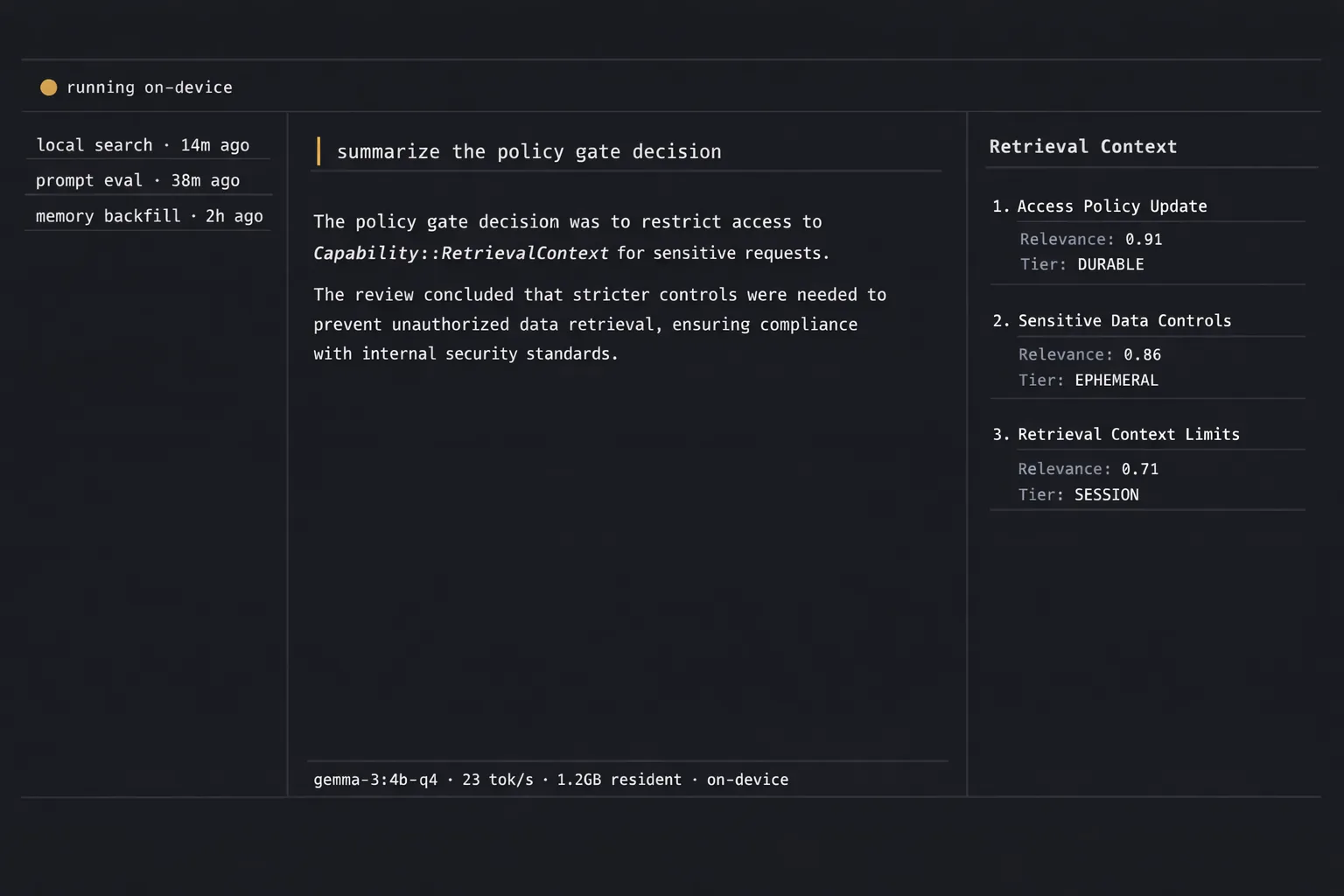
Retrieval is the boundary where the model becomes mine.
System
Seven independent engines on a shared bus, each with an explicit contract. Sibling layers do not import each other; they coordinate through typed events and a single policy gate. The boundary is enforced by a workspace-level linter that fails CI on a forbidden import edge. That linter is the only reason the architecture survives contact with my own shortcuts.
| Layer | Implementation | Purpose |
|---|---|---|
| Shell | Tauri 2.x | Native window · IPC · single binary |
| Core | Rust + tokio | Layered engines · capability bus · audit |
| Inference | Ollama · gemma4:e4b | Local text model · 9.6 GB · 128K ctx |
| Embeddings | bge-m3 · 1024-d | Retrieval lane · CPU-bounded |
| Storage | SQLite + sqlite-vec | Durable memory · WAL · single writer |
| UI | React 19 + Vite | Chat surface · presence · onboarding |
// Embed → query_nearest → fetch_one → rank, with one
// hard wall-clock deadline across the whole pipeline.
// On exceed: warn once, return empty. No silent fallback.
pub fn run_retrieval_context(
state: &AppState,
session_id: &str,
utterance: &str,
max_items: usize,
deadline: Duration,
) -> Vec<RetrievalHit> {
if max_items == 0 || !state.embeddings_enabled() {
return Vec::new();
}
// L5 policy gate — one audit row per retrieval call.
let decision = state.policy_evaluate(
Capability::RetrievalContext,
ResourceScope::None,
);
if !matches!(decision, Decision::Allow { .. }) {
return Vec::new();
}
let deadline_at = Instant::now() + deadline;
let query = timed(deadline_at, || state.embed(utterance))?;
let hits = timed(deadline_at, || state.query_nearest(&query))?;
let rows = timed(deadline_at, || state.fetch_rows(&hits))?;
rank(rows, RECENCY_WEIGHT_ALPHA, max_items)
}
{
"request_id": "retrieval-1714312880412",
"capability": "RetrievalContext",
"decision": "Allow",
"deadline_ms": 5000,
"embed_ms": 187,
"query_ms": 42,
"fetch_ms": 9,
"rank_alpha": 0.1,
"hits": [
{ "id": "msg_2419", "score": 0.821, "tier": "durable" },
{ "id": "msg_2210", "score": 0.804, "tier": "session" },
{ "id": "msg_1988", "score": 0.793, "tier": "session" }
],
"bailout": false
}
Running it locally
Companion is source-only at this stage — there is no signed installer yet because there is no signed installer worth shipping yet. The build chain is small. Rust toolchain, Node, Ollama, the model and embedding pulls; that’s it. The first run brings up an empty profile and the policy gate in the most conservative posture; you grant capabilities as you use them, and every grant is a row in the audit log.
build.shshell# prerequisites: rustup, node 20+, pnpm, Ollama
git clone https://github.com/dbhavery/aether
cd aether
ollama pull gemma4:e4b
ollama pull bge-m3
pnpm install
pnpm tauri devTargets macOS 13+, Linux x86_64/arm64, Windows 11. Disk: ~12 GB for both model pulls. Runtime: ~6 GB resident during inference on the e4b variant. The repo’s CONTRIBUTING.md covers per-platform setup quirks.
Acknowledgments
Three notes on what this assembly owes. First, the runtime: Tauri wraps a Rust core (tokio, SQLite via sqlite-vec, hardware probes from sysinfo and wgpu) into a single binary that opens like a native window. Second, the model layer: the Gemma weights from Google DeepMind, served via Ollama, with BGE-M3 doing retrieval. Third, the boundaries: cargo-deny and a small ESLint rule keep the layered architecture from rotting. The interesting parts of this project are the parts I wrote on top of work other people did first.