62 requirements · 3 frameworks · under 10 seconds end to end
Auditor
The internal name is Sentinel; the showcase name is Auditor.
- Built for:
- Founders and small teams who need to know where their actual policies stand against a real compliance framework before a real audit starts.
- Not built for:
- Replacing a human auditor. The output is a gap report and a remediation plan — not an attestation.
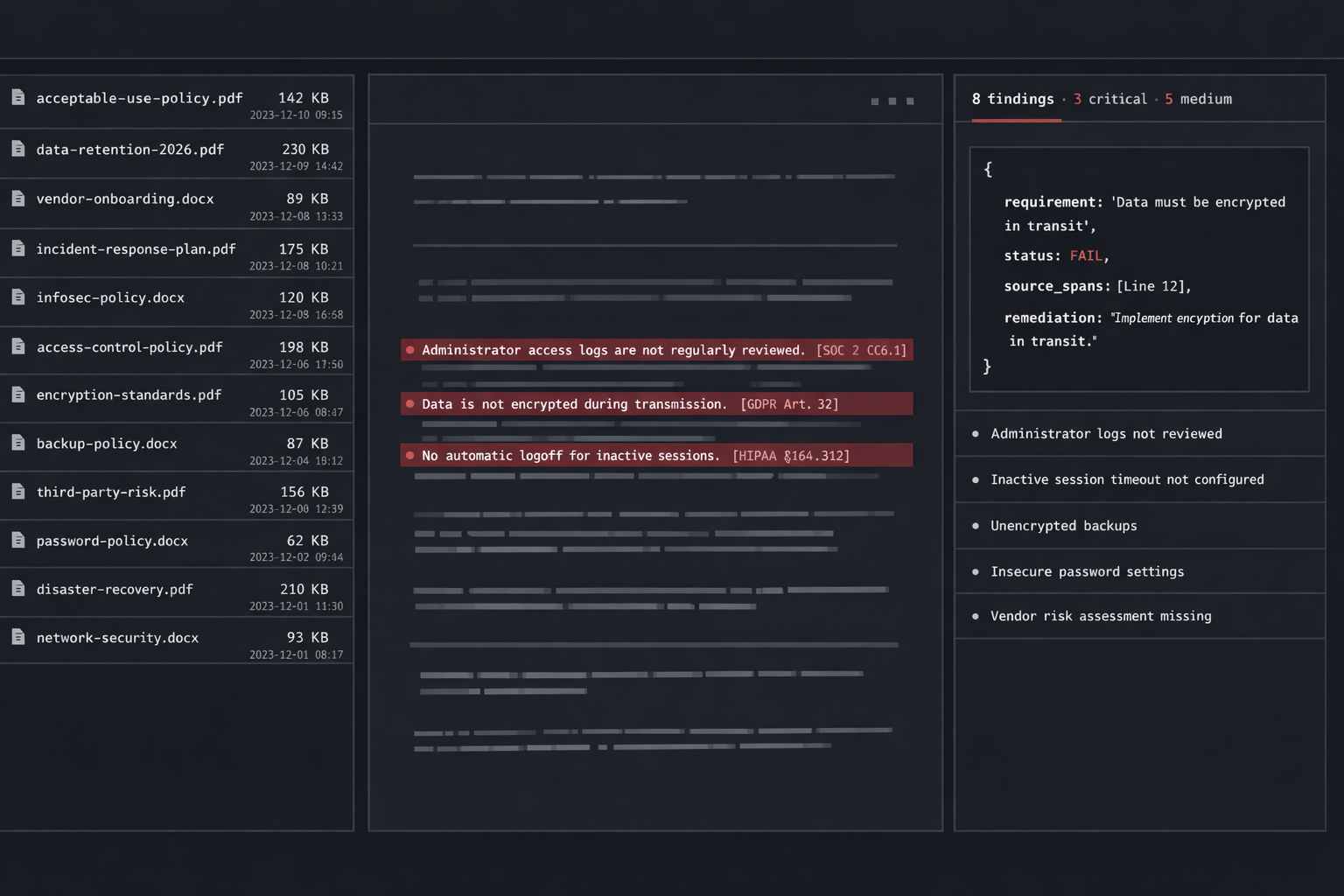
A compliance audit reads existing policies against a structured set of requirements. That’s a job an LLM should be excellent at, if you give it the structure. Auditor scans your documentation against 62 real requirements across SOC 2, GDPR, and HIPAA, in seconds, and returns a per-requirement verdict that holds up under a human read.
The problem
Pre-audit gap analysis is a six-week consulting engagement that produces a spreadsheet. The work is real, the price is reasonable for what it costs the consultancy, and the spreadsheet itself is mechanical: read each policy, check it against each requirement, mark compliant / partial / failing, write a sentence of justification.
Auditor automates that mechanical layer and returns the same shape of artifact in seconds. A human still owns the remediation plan; the part the LLM owns is the part where it’s actually better than a tired consultant on a Friday.
Decisions
kept2026-Q1
A typed requirement schema, hand-curated from the source frameworks. The 62 requirements are real text from real specs — not paraphrased. The LLM never gets to interpret what a requirement means; it gets the requirement verbatim.
cut2026-Q1
Free-form “ask the model anything” chat. The output shape is a structured per-requirement verdict; opening a chat surface invites the model into territory where it should not be making calls. The constrained shape is the safety.
refusedongoing
Issuing attestations or claiming the output is audit-ready. The output is a gap report. A human auditor is still the only path to an attestation, and the product should not pretend otherwise.
System
| Layer | Implementation | Purpose |
|---|---|---|
| Ingest | Markdown · DOCX · PDF | Policy text gets normalized to plain prose |
| Frameworks | SOC 2 · GDPR · HIPAA | 62 requirements, hand-curated, verbatim |
| Match | BM25 + embedding | Locate relevant policy passages per requirement |
| Verdict | Constrained LLM call | Compliant / partial / failing + justification |
| Report | Structured output | JSON · then DOCX · with quoted source spans |
# The model never decides "what does the requirement mean."
# The requirement is verbatim from the spec. The model only
# decides "does this policy text satisfy this requirement,
# and where in the source does it say so."
class Verdict(BaseModel):
requirement_id: str
framework: Literal["SOC2", "GDPR", "HIPAA"]
status: Literal["compliant", "partial", "failing"]
justification: str
source_spans: list[SourceSpan] # quoted, not paraphrased
async def adjudicate(
requirement: Requirement,
matched: list[PolicyPassage],
) -> Verdict:
return await llm.respond(
system=VERDICT_SYSTEM_PROMPT,
user=render(requirement, matched),
response_model=Verdict, # constrained shape
temperature=0,
)
{
"requirement_id": "SOC2-CC6.1",
"framework": "SOC2",
"status": "partial",
"justification": "Logical access controls are documented for production systems but the policy does not specify periodic access review cadence. The framework requires quarterly review.",
"source_spans": [
{
"doc": "policies/access-control.md",
"line": 42,
"text": "All production access is gated by SSO and MFA, granted on a least-privilege basis."
}
],
"remediation": "Add a quarterly access-review cadence to the access-control policy and a procedure for the review owner to attest."
}
Acknowledgments
Auditor stands on the published SOC 2, GDPR, and HIPAA reference texts, on every compliance team that’s opened a checklist long enough to formalize what the requirements actually demand, and on the LLM ecosystem that made “structured verdict over a span of source text” into a one-API-call task.
← Index